

Se você é um analista ou cientista de dados, ou pretende se tornar um, em algum momento vai acabar se deparando com a biblioteca Pandas. Em sua essência, o Pandas é uma biblioteca open-source que fornece ferramentas de manipulação e análise de dados para a linguagem de programação Python.
No entanto, ao olhar a documentação da biblioteca, é normal ficar um pouco confuso inicialmente com tantas funcionalidades, além de não saber por onde começar. Por isso, montamos uma lista com as principais e mais importantes funções que você irá precisar no seu dia a dia como profissional de dados.
1. Apelido da biblioteca Pandas
O primeiro tópico não é exatamente uma função, mas uma dica bem importante, que é a convenção ou o apelido da biblioteca Pandas.
Sempre que importamos uma biblioteca no Python, podemos chamá-la por um apelido; no caso do Pandas, normalmente se usa o “pd”. Essa prática é útil, pois dessa forma fica mais fácil para outros programadores – ou até mesmo para você – identificar a biblioteca quando estiver analisando o código.
import pandas as pd2. Lendo e escrevendo em diversos arquivos com biblioteca Pandas
Ao lidar com dados, é crucial saber como manipular diferentes fontes de informações.
Uma fonte muito comum é o csv (arquivo com valores separados por vírgulas, do inglês comma-separated values). Após importada a biblioteca Pandas, basta uma linha de código para lê-lo, passando como parâmetro da função o caminho no qual se encontra o arquivo, conforme o exemplo abaixo:
df = pd.read_csv(“meu_arquivo.csv”) Trabalhando com planilhas Excel
Analistas de dados frequentemente usam planilhas do Excel. Inclusive, também é possível lê-las com a biblioteca Pandas; dessa forma, basta novamente passar o caminho do arquivo e a planilha que deseja visualizar:
df = pd.read_excel((open(“meu_arquivo.xlsx”, “rb”), sheet_name=”planilha1”)
Acesso direto a planilhas do Google Sheets
Se você utiliza as planilhas do Google Sheets como fonte de dados, também conseguirá acessar suas informações sem precisar baixar sua planilha e importá-la em seu script toda vez. Para isso, gere um link de acesso a ela e acesse-a com o método ‘read_csv’.
Para gerar esse link, selecione as opções Arquivo → Compartilhar → Publicar na Web. Logo após, aparecerão várias opções de como compartilhar esse arquivo, uma delas sendo csv. Depois, é só passar o link gerado como parâmetro da função.


df = pd.read_csv(“url gerada”)Salvando dados com Pandas
Após ler e manipular os dados em seu dataframe, é interessante salvá-los em algum arquivo, e a biblioteca Pandas também fornece esse tipo de solução, com as funções abaixo, semelhante às de leitura:
df.to_csv(“novo_arquivo.csv”)
df.to_excel(“novo_arquivo.xlsx”, sheet_name=”nova_planilha”)Trabalhando com JSON
Como uma dica extra neste tópico, podemos abordar o formato JSON, muito comum para quem quer trabalhar com APIs ou scripts de web scraping (parte fundamental do cotidiano do analista de dados). A biblioteca Pandas também fornece a possibilidade de ler dados nesse formato de maneira bem simples:
pd.read_json("meu_arquivo.json", orient='index')Explorando mais formatos
Essa biblioteca oferece formas de ler e escrever em diversos formatos de arquivo, contudo vamos abordar apenas as mais importantes neste artigo. Ou seja, é fundamental acessar a sua documentação e explorar todas as possibilidades.
3. Head e Tail na biblioteca Pandas
Depois de importar os seus dados, você vai querer visualizá-los antes de começar a fazer as manipulações e análises essenciais na rotina de um analista de dados e, muitas vezes, não queremos visualizar a base de dados completa em uma análise inicial.
Para isso, a biblioteca Pandas possui duas funções interessantes: a ‘Head’, que possibilita ver apenas as primeiras linhas do dataframe; e a ‘Tail’, que nos possibilita visualizar as últimas linhas.
Abaixo temos um exemplo de visualização das primeiras 10 linhas de um dataframe e também as suas últimas 5 (a quantidade de linhas pode ser passada como parâmetro da função):
df.head(10)
df.tail(5)
4. Removendo linhas e colunas com o Pandas
Agora que você já deu uma primeira olhada nos seus dados, pode começar a manipular o seu dataframe. Nesta etapa, é possível que você queira eliminar algumas linhas ou colunas e, com o Pandas, isso pode ser feito de maneira muito simples de duas formas:
# Remover linhas pelo index: passe o índice das linhas que deseja excluir como lista com o método drop.
df.drop([0, 2, 15])# Remover colunas pelo nome: passe o nome da coluna que deseja excluir como parâmetro do método e indique o eixo como 1, que representa o eixo das colunas.
df.drop(‘Coluna B’, axis=1)5. Criando uma nova coluna com o Pandas
Além de remover colunas, pode ser que você também queira adicionar algumas novas à sua base de dados. Para tal, informe o nome da nova coluna e o seu conteúdo, que pode ser tanto um texto quanto uma operação com outras colunas.
Dado o seguinte dataframe:
| País | População | Extensão territorial (Km²) |
| China | 1.439.323.776 | 9.596.961 |
| Índia | 1.380.004.385 | 3.287.590 |
| Estados Unidos | 331.002.651 | 9.371.174 |
| Indonésia | 273.523.615 | 1.904.569 |
| Brasil | 212.559.417 | 8.515.767 |
| Rússia | 145.934.462 | 17.098.246 |
| México | 128.932.753 | 1.964.375 |
| República Democrática do Congo | 89.561.403 | 2.344.858 |
| Irã | 83.992.949 | 1.628.750 |
Podemos criar uma nova coluna com um texto qualquer:
df[“Nova Coluna”] = “A”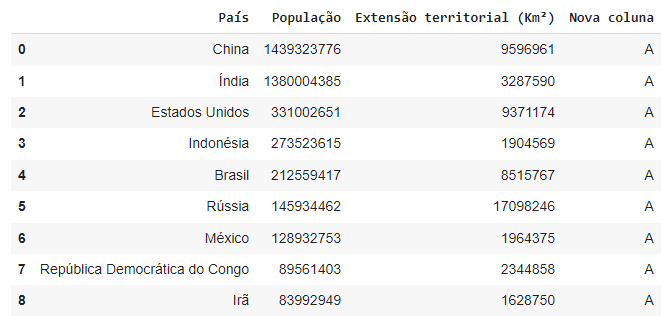
Ou com uma operação entre as colunas: População dividido pela Extensão territorial, por exemplo.
df[“Pop por Km²”] = df[“População”] / df[“Extensão territorial (Km²)”]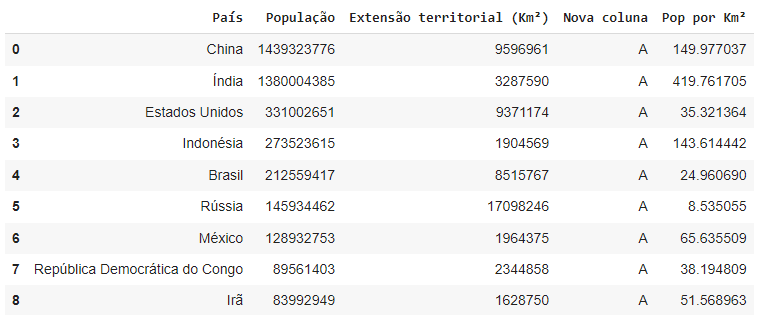
6. Renomeando colunas de um dataframe
É comum, durante a manipulação dos dados em um dataset, preferirmos trocar o nome das colunas por conveniência ou praticidade (tirar espaços, acentos, etc.). Nesse caso, atribua novos nomes de colunas ao atributo ‘df.columns’. Renomeando o dataset anterior, ficaria da seguinte forma:
df.columns = [“pais”, “populacao”, “extensao_territorial”, “nova_coluna”, “pop_por_km”]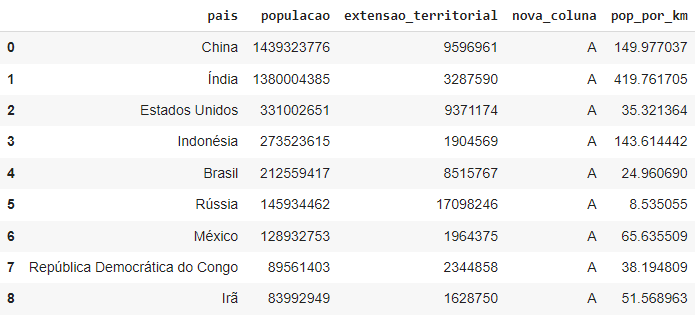
7. Informações do dataframe
É importante para todo analista de dados fazer análises precisas e rápidas sobre os seus dados. Para esse fim, o Pandas disponibiliza uma série de atributos e métodos que auxiliam a sintetizar informações essenciais para análises mais complexas.
Atributos
#df.shape: exibe a quantidade de linhas e colunas, respectivamente, do seu dataframe.
df.shape
#df.columns: exibe o nome das colunas presentes no dataframe.
df.columns
Métodos
#df.count(): exibe a contagem de dados não-nulos em cada coluna.
df.count()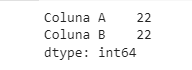
#df.isna().sum(): exibe a contagem de dados nulos em cada coluna.
df.isna().sum()
#df.unique(): exibe a contagem de valores únicos em cada coluna.
df.unique()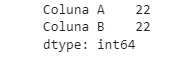
#df.value_counts(): exibe a contagem de valores por registro em cada coluna. Para o seguinte o dataset, o resultado seria:
| Trilha | Curso |
| Data Science | ML |
| Dashboards | MyBudget |
| Dashboards | MyBudget |
| Data Science | ML |
| Trading | Quant |
| Data Science | ML |
| Data Science | ML |
| Dashboards | MyBudget |
| Dashboards | MyBudget |
| Trading | Quant |
| Dashboards | MyBudget |
| Data Science | ML |
df[‘Trilha’].value_counts()
8. Descrição dos dados
Na carreira de cientista de dados, é importante ter conhecimento de alguns conceitos de estatística, e o Pandas oferece um método muito útil com a descrição de algumas estatísticas básicas de suas variáveis. Por exemplo, para o dataset abaixo, o resultado seria:
| País | População | Extensão territorial (Km²) |
| China | 1.439.323.776 | 9.596.961 |
| Índia | 1.380.004.385 | 3.287.590 |
| Estados Unidos | 331.002.651 | 9.371.174 |
| Indonésia | 273.523.615 | 1.904.569 |
| Brasil | 212.559.417 | 8.515.767 |
| Rússia | 145.934.462 | 17.098.246 |
| México | 128.932.753 | 1.964.375 |
| República Democrática do Congo | 89.561.403 | 2.344.858 |
| Irã | 83.992.949 | 1.628.750 |
df.describe()
Aqui temos informação de contagem de valores por coluna do dataframe, além da média, desvio padrão, valor mínimo e máximo e percentis.
9. Ordenando valores
Caso precise ordenar os dados de seu dataframe, o Pandas conta com o método ‘sort_values’. Basta passar como parâmetro a coluna na qual os dados serão ordenados.
Por padrão, eles serão ordenados de maneira ascendente. Portanto, caso queira que a ordenação seja de forma descendente, é preciso passar essa informação como parâmetro.
Veja abaixo:
#Ordenação ascendente
df.sort_values(by=”coluna A”, ascending=True)#Ordenação descendente
df.sort_values(by=”coluna A”, ascending=False)10. Filtrando o dataframe
Será muito útil durante suas análises fazer filtros nos seus dataframes. O Pandas oferece essa funcionalidade de duas maneiras: selecionando linha e coluna a ser filtrada ou filtrando por condições específicas.
Veja nos exemplos abaixo:
#Selecionando a primeira linha da coluna País
df.loc[0, “País”]#Filtrando o dataframe para mostrar apenas os registros com População maior que 10.000.
df[df[“População”] >= 10000]Como aprender mais sobre a biblioteca Pandas?
O Pandas é uma das ferramentas mais importantes para quem tem vontade de ingressar na carreira de dados, pois é muito útil tanto para visualização quanto para análise de dados. Essa versatilidade é impulsionada pela praticidade e escalabilidade da biblioteca, que não apenas oferece soluções eficientes, mas também otimiza o código, eliminando a necessidade de numerosos loops ‘for’ e ‘while’ em tarefas simples.
Embora este artigo tenha como objetivo mostrar as principais funções que o profissional de dados usará no dia a dia, há outras tantas funcionalidades dentro da biblioteca que poderão ser úteis. Você consegue aprender mais sobre elas no curso Analisando Dados com Pandas, da Asimov Academy, o qual aprofunda esses conceitos e aplica-os na prática. Além disso, explore também nossos cursos de Visualização de Dados e Data Science e expanda as fronteiras do conhecimento em dados!