
Conheça 7 dicas de Python avançado que todo programador experiente precisa saber, mas que são pouco conhecidas, como decoradores, cacheamento, memoização e mais.
Para se diferenciar como programador e se manter competitivo no mercado de trabalho, é fundamental ter bons truques na manga para ganhar eficiência, produtividade e gerar valor nos serviços prestados. Por essa razão, apresentaremos aqui, de forma prática e breve, algumas dicas avançadas de Python, com termos que programadores iniciantes provavelmente nunca ouviram, mas que são fundamentais para os programadores experientes.
Essas dicas definitivamente elevarão você a um outro patamar, e entendê-las profundamente significa que você é um bom programador.
1. Cacheando Valores
A linguagem de programação Python possui diversos pontos positivos, como velocidade de desenvolvimento, fácil legibilidade, alocação automática de memória e uma comunidade muito ativa. No entanto, todo bônus vem com seu ônus: Python não é uma linguagem computacionalmente eficiente. Ou seja, um código que realiza as mesmas operações em uma linguagem de mais baixo nível (como C, por exemplo) provavelmente será mais rápido.
Para evitar que isso se torne um problema para o usuário, é importante que o desenvolvedor de uma aplicação em Python domine algumas ferramentas básicas que aumentam a velocidade do código, e o cacheamento é uma delas.
O cache é basicamente um armazenamento de dados que o programador utiliza com frequência em seu código, de forma que não precise gerar o mesmo dado mais do que uma vez.
Exemplo de código com cache
CACHE = {}
def fatorial_com_cache(valor):
if valor in CACHE:
return CACHE[valor]
else:
if valor <= 1:
CACHE[valor] = 1
return CACHE[valor]
else:
CACHE[valor] = valor * fatorial_com_cache(valor - 1)
return CACHE[valor]Exemplo de código sem cache
def fatorial_sem_cache(valor):
if valor <= 1:
return 1
else:
return valor * fatorial_sem_cache(valor - 1)
As duas funções são idênticas, produzem o mesmo resultado, mas a função que utiliza cache é extremamente mais eficiente quando utilizada diversas vezes. Provaremos isso no exemplo a seguir!
2. Utilizando uma função com argumento de outra
A beleza da orientação a objetos é a flexibilidade que isso concede ao programador. Python trata as suas funções como objetos e, ao mesmo tempo, as funções podem receber tanto variáveis quanto objetos como argumentos. Isso permite que uma função receba outra função como argumento.
No exemplo abaixo, criamos uma função que mede o tempo de execução de outras funções. Além disso, testamos se, de fato, os caches tornaram o nosso código mais eficiente.
from time import time
def tempo_da_funcao(func, *args):
inicio = time()
resultado = func(*args)
fim = time()
print(f'A funcao {func.__name__} demorou {(fim-inicio) * 1000 * 1000} microsegundos para rodar e o resultado foi {resultado}')
for i in range(5):
tempo_da_funcao(fatorial_com_cache, 50)
tempo_da_funcao(fatorial_sem_cache, 50)
Por aqui, os resultados foram estes:
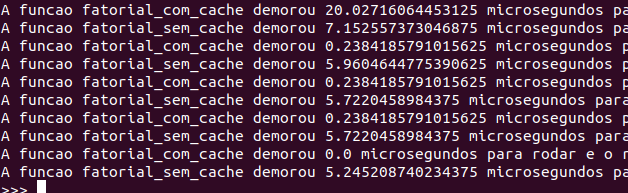
Como esperávamos, a primeira vez em que chamamos a função com cache é mais lenta, pois ela precisa salvar os dados (adicionando um passo a mais a ser rodado). Porém, após gerados os valores, a função torna-se 20 vezes mais rápida em comparação à que não utiliza cache!
Da mesma forma em que uma função pode ser usada como argumento, ela também pode ser retornada como resultado de uma outra função. Essas características do Python permitem a criação de uma classe de funções muito úteis, os decoradores, que são funções que adicionam capacidades a outras funções sem a necessidade de modificá-las.
3. Memoização com lru_cache
Um decorador muito utilizado em Python avançado é o lru_cache. Ele é um decorador para memoização de funções.
Memoização é a técnica de armazenar resultados de funções custosas computacionalmente e retornar o mesmo resultado quando os mesmos parâmetros forem passados. Basicamente, é o que fizemos anteriormente com a função fatorial_com_cache.
A lru_cache faz esse trabalho para nós automaticamente, sem a necessidade de criarmos uma variável CACHE e modificarmos nossa função.
from functools import lru_cache
@lru_cache
def fatorial_com_cache(valor):
if valor <= 1:
return 1
else:
return valor * fatorial_sem_cache(valor - 1)
def fatorial_sem_cache(valor):
if valor <= 1:
return 1
else:
return valor * fatorial_sem_cache(valor - 1)
for i in range(5):
tempo_da_funcao(fatorial_com_cache, 50)
tempo_da_funcao(fatorial_sem_cache, 50)
4. Memoização com TTLCache
Outra forma de memoização é utilizando TTLCache. Esse objeto faz parte do pacote cachetools, que pode ser instalado com o comando pip install cachetools.
O diferencial aqui é a possibilidade de definir o tamanho máximo do cache (para garantir que o cache não consuma muito espaço na memória RAM) e o tempo de vida (TTL, da sigla em inglês “time to live”), que é o tempo máximo que um valor fica armazenado no cache. O tempo de vida é bastante útil em aplicações nas quais desejamos armazenar um valor por um tempo não tão longo, pois existe a necessidade de atualizar a output da função.
O trecho de código abaixo mostra como podemos implementar a função fatorial_com_cache com o TTLCache.
from cachetools import cached, TTLCache
cache = TTLCache(maxsize=100, ttl=86400)
@cached(cache)
def fatorial_com_cache(valor):
if valor <= 1:
return 1
else:
return valor * fatorial_sem_cache(valor - 1)
5. Rodando funções ao finalizar o código
Falando em decoradores, outro muito interessante é o register. Quando se trata de Python avançado, os programadores o utilizam para realizar uma ação quando um código termina a sua execução.
from atexit import register
@register
def adeus():
print(" Adeus!")
exit()
6. Generators para diminuir o consumo de memória RAM
Talvez você já tenha ouvido falar em generators em Python, mas não saiba qual é a sua utilidade tampouco quando utilizá-los. Eles podem ser extremamente úteis quando estamos tratando com conjuntos muito grandes de dados.
Por exemplo, ao trabalharmos com a iteração em uma lista muito grande ou com a leitura de um arquivo csv muito grande, os generators reduzem muito o consumo de memória. Isso porque um generator possui a habilidade de gerar um número por vez, somente quando ele é necessário. Veja exemplos:
nums_sem_generator = [i * i for i in range(10_000_000)]
sum(nums_sem_generator)
nums_com_generator = (i * i for i in range(10_000_000))
sum(nums_com_generator)
No exemplo sem generator, cria-se primeiro a lista para posteriormente calcular o valor da soma. Isso, em termos de memória RAM, é ineficiente, pois seria muito melhor calcular o primeiro valor e somá-lo ao total, depois calcular o segundo valor e somá-lo ao total, e assim sucessivamente até o último valor. É justamente isso que o generator faz, ele só gera o número quando há necessidade de usá-lo e de forma automática.
import csv
def ler_csv_sem_generators():
with open('dataset_grande.csv', 'r') as f:
leitor = csv.reader(f)
return [linha for linha in leitor]
resultado_0 = ler_csv_sem_generators()
def ler_csv_com_generators():
with open('dataset_grande.csv', 'r') as f:
leitor = csv.reader(f)
for linha in leitor:
yield linha
resultado_1 = [linha for linha in ler_csv_com_generators()]
A função ler_csv_com_generators faz um loop por cada linha e cria uma linha por vez, diminuindo a chance de termos algum problema de memória na leitura.
7. Usando Data Class
Desde a versão 3.7, Python oferece a Data Class, um tipo especial de classe para dados de forma nativa. Essa classe tem características únicas que a diferencia de classes normais ou de simplesmente salvar valores em dicionários.
Por exemplo, Data Class permite a fácil comparação entre instâncias diferentes, pois você pode facilmente printar os valores armazenados em uma Data Class e ela necessita de sugestão de tipos (type hints) – o que facilita na hora de depurar o código.
from dataclasses import dataclass
@dataclass
class Carta:
valor: str
naipe: str
carta = Carta("Q", "espadas")
print(carta == carta)
print(carta.valor)
print(carta)
Dica extra de Python avançado: utilize * para dar flexibilidade aos argumentos da sua função
Se você estiver criando um código que será usado por muitas outras pessoas, como uma API, é uma boa prática permitir flexibilidade nos parâmetros que são passados. Você pode fazer isso especificando valores-padrão para cada parâmetro ou pode usar *.
def declaracao_default(p1=None, p2=None, p3=None): # NÃO FAÇA ISSO
print([p1, p2, p3])
def argumentos_posicionais(*args): #FAÇA ISTO
print(args)
def argumentos_por_palavra_chave(**kwargs): #OU ISTO
print(kwargs)
declaracao_default(p1=1, p2=2, p3=3)
argumentos_posicionais(1,2,3)
argumentos_por_palavra_chave(p1=1, p2=2, p3=3)
Desenvolva sua identidade como programador!
Essas são algumas dicas de Python avançado que fui desenvolvendo com os meus anos de experiência e que, por diferentes motivos, são importantes no meu dia a dia de programador.
Cada pessoa desenvolve formas diferentes de se tornar mais produtivo, e isso depende muito da sua área de atuação. O importante é que você desenvolva a sua forma de trabalho e aprimore-a com o tempo, criando assim uma identidade própria.
Essa identidade, quando levada para um novo ambiente de trabalho, é muito importante para a equipe, assim você tem ferramentas para compartilhar que enriquecem o todo. Inclusive, essa é uma das principais habilidades de um programador experiente: ter ferramentas para compartilhar.